

最近买了 Ray Wenderlish 上面的 《Machine Learning by Tutorials》一书看了看,对机器学习有了进一步的理解。
这本书前面几章特别适合 iOS 背景的同学,因为相关的实践都是直接在 Xcode 环境下做的。
以下是我的一些小结。
机器学习基础概念
首先我们需要理解一些非常基础的概念。
深度学习
虽然严格意义上的机器学习定义范围很广,但是这本书讲的其实是指深度学习(Deep Learning),这也是当前最火的机器学习研究领域。
深度学习其实是一项相对有些年头的研究成果了,它之所以最近 5 年才这么火,主要是因为人们发现了可以用 GPU 来加速其计算过程。原本需要算几年才能训练出来的模型,现在在 GPU 的帮助下可以在几天训练出来了。
这样,一项原本理论上完美但是实际上困难的技术终于落地了。Google 旗下的 DeepMind 研究出来的围棋 AI Alpha Zero,就是在 40 天的训练后,超过了世界围棋冠军以及它的前辈们。

深度学习之所以名字中带深度,是因为它的模型是分层的,这一层一层的模型与人类的大脑皮层类似,我们把它叫做神经网络(Neural Network)。
模型
模型代表的是训练(Training)出来的神经网络,训练的方式有三种:
- 监督学习(supervised learning)。在训练的时候告诉模型什么是对的,什么是错的,让模型学习。
- 非监督学习(unsupervised learning)。主要是通过 k-means 之类的算法,让模型自己从数据中找规律。
- 强化学习(reinforcement learning)。设立一些简单的规则,让模型通过正向奖励和负向惩罚来训练。
模型在训练的时候会抽取特征(feature),比如一个预测房价的模型,那么它的 feature 可能有房间数,面积,楼层,位置,朝向等。
大多数情况下,为了让模型训练出好的能力,都需要进行大量的训练。而很多大量的训练数据,都是通用人工标注来完成的。小猿搜题的拍照搜题算法就是基于深度学习的,为此我们长年维持着一个上百人的标注团队,用于提升模型的准确度。所以我们的同事戏称:
人工智能是有多少人工就有多少智能。
这也是我去年为什么重仓 Tesla 的原因,在相关法律法规还不完善的情况下,特斯拉的自动驾驶算法已经靠它全球几十万辆车收集了海量的数据。有一些甚至是自动驾驶算法的事故数据,而这些海量数据是自动驾驶技术的核心优势。除了 Google,没有第二家有这么海量的数据,特斯拉的自动驾驶算法就值 300 亿美金。
神经网络的工作原理
这本书用了一种很简单的方式解释了神经网络的工作原理。
我们首先定义任务:设计一个神经网络,从一堆图片中区分出猫和狗的图片。
其实任何数据,我们都可以把它看作一段输入的序列。比如一张图片,我们可以看成图片的点的序列,每个点我们又可以看成一个 RGB 值的序列,这样我们就可以把一张图片,变成一个序列。
假设所有图片长宽是 NxN 的,那么它就包含 NxN 个点,每个点有 R,G,B 三个值,这样就是 3xNxN 个值。我们知道,在二维的平面,所有点都是 [x,y] 两个值的。在三维空间,所有点都是 [x,y,z] 三个值的。所以我们当前任务的图片,如果长宽都一样,那么就都是 3xNxN 维空间上的一个点。
这一堆图片,其实就是 3xNxN 维空间上的一堆点。
而神经网络的任务,就是在这个空间中,找出一种方式,把这些点分成两堆,其中一堆全是猫,另一堆全是狗。
为了更形象地举例,书中拿 3 维空间举例,神经网络的任务就是找出一个平面,把下面的点分成两堆。
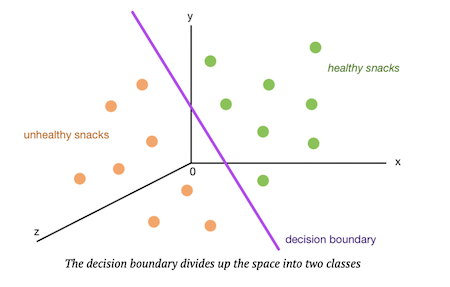
但是,很多时候,这些点明显不是像上面这样排列的,它们很可能混淆在一起,像下面这样:
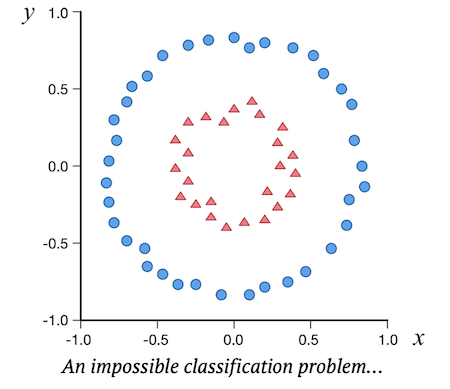
所以,你需要进行变换,把这些点通过一些变换,映射到另一些点上面,我们希望通过这些变换,最终可以找到一个平面,把这些点很方便地分割开。拿图中的例子来说,如果你可以变换成下面这样,我想你用肉眼就可以找到分割方式了。
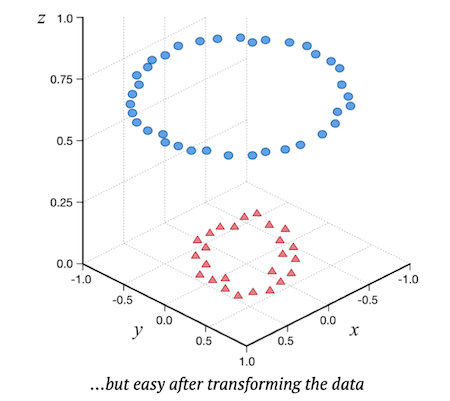
神经网络的厉害之处在于,它会自动进行这种变换尝试,最终找到一种尽可能好的变换,这也就是训练模型的过程。而最常见的变换方式就是卷积(convolutions)。
卷积神经网络(CNN)也是现在最常见的处理图像类的深度学习模型。卷积运算被大量用在图像显示处理中,这也是为什么深度学习更适合使用 GPU 而不是 CPU 的原因。
CNN 和 RNN
卷积神经网络(CNN) 和 (循环神经网络)RNN 是当前最常见的两种神经网络。
CNN 通过卷积来完成神经网络的变换,通常情况下适用于图像一类的场景,比如人脸识别。CNN 通过卷积,将图像的特征一步步地提取,从最初的像素点,慢慢变成边,再慢慢提取出小的部件,最终能够识别出复杂的东西。比如下图就是 CNN 人脸识别的过程(来自参考资料2):
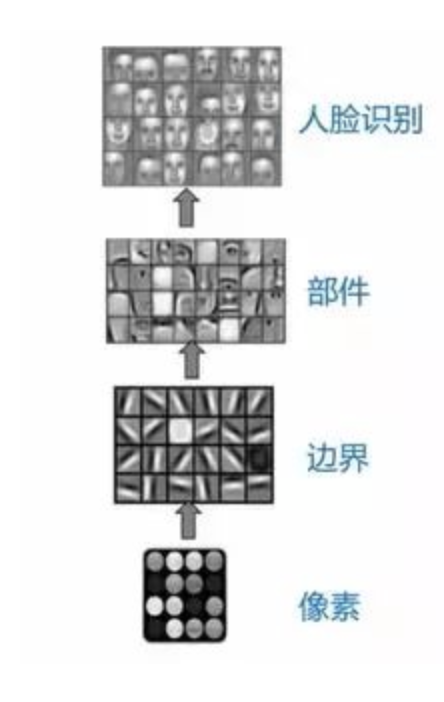
CNN 通常要求输入数据是相同规格的,刚刚我们提到那个识别小猫小狗的问题,其实用 CNN 的话,首先需要做的就是把图片缩放成一样的尺寸。但是有些时候,我们并不能很方便地做这种事情。
例如:我们要用 CNN 做一个语言翻译模型。我们不可能让所有的语言输入的时候长度都是一样的。这个时候,RNN 的优势就体现了。RNN 更注意关注输入数据的连续性,并且每次运算的时候,可以反复地把当前层的输出又当作输入进行运算。
拿数据结构来说,CNN 应该是一个有向无环图,而 RNN 是一个有向有环图。
如何理解卷积
卷积如果上数学描述来解释,容易让人晕。我打一个比方吧:
卷积就是拿一个矩阵,我们可以把它想像成一个盖子,这个盖子在目标图形上不停地移动。每次移动的时候,这个矩阵就和目标图形上被“盖住”的区域做一个操作,这个操作形成一个新的数字,填到新的图形中。
具体的操作方式是:将这个矩阵和被盖住的矩阵对应位置做乘积,然后求和。下面是一个示意图(来自参考资料1):
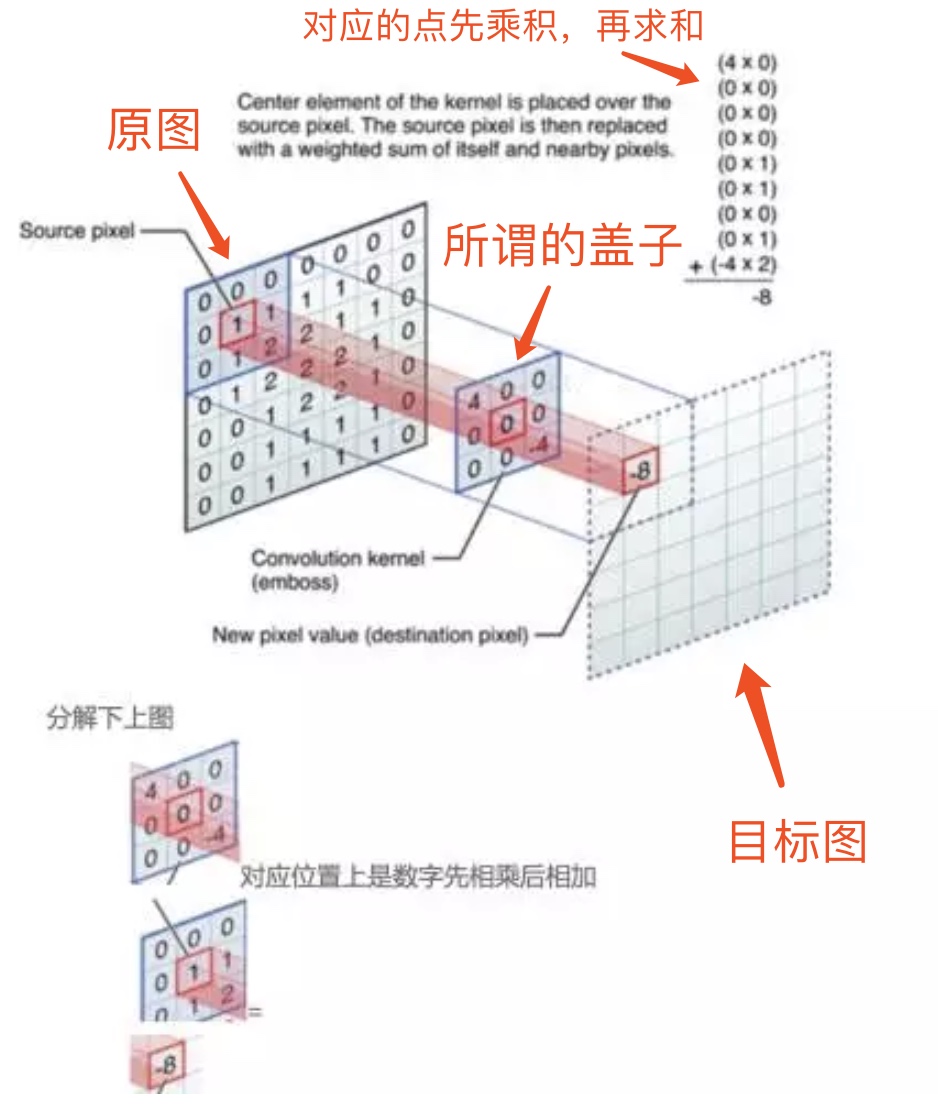
卷积的公式选择得好,就有助于提取图像中关键的信息,下面是一个示意,可以看到花瓣通过卷积,在目标图形上得到明显地体现,而其它信息被抹去了。(来自参考资料1)。

使用 Create ML 来训练数据
我们可以使用 Xcode 自带的 Create ML 来训练一些基础的深度学习模型,然后应用到我们的 App 上。苹果系统自带的 Core ML 和 Metal 可以很方便地在底层提供这些支持。下面是一个例子。
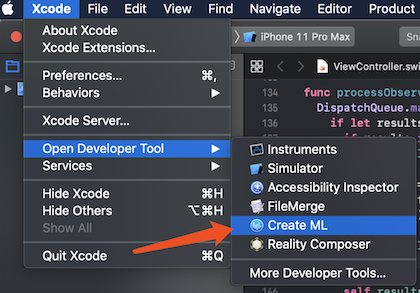
从 Xcode 的菜单 Xcode -> Open Developer Tool -> Create ML 可以打开 Create ML 工具。
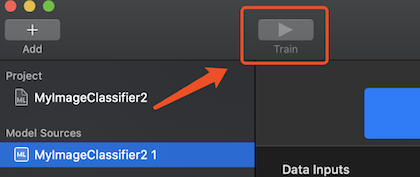
然后,新建一个图像分类的模型,然后选择 Input,将需要训练的图片导入进入。每一种类型的图片需要放在同一个目录。导入之后可以看到 Create ML 识别出图像的种类数(class)。点击工具栏上的训练按钮即可开始训练。
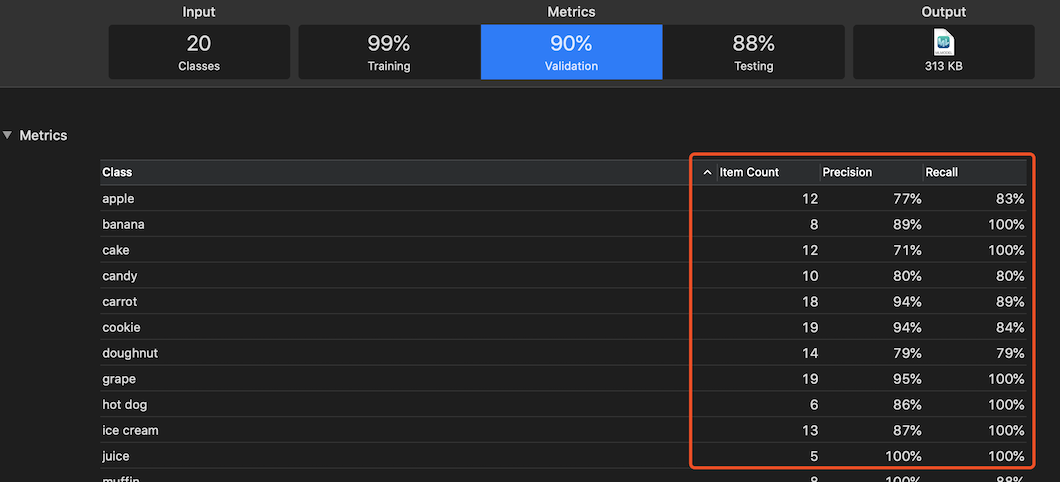
训练结束后,可以看到 准确率(precision)和 召回率(recall)。
直接拖动 output 中的那个文件到 Finder 中,即可将训练好的模型导出。
在代码中应用训练好的模型也非常方便,将模型文件拖入到 Xcode 工程中,就可以看到这个模型对应的类名和方法定义了。可以直接在 Xcode 中初始化这个模型,然后调用其 prediction 方法进行图像的分类。
小结
- 深度学习其实是利用神经网络的变换,来对训练数据进行学习的技术。
- 大部分的深度学习案例都需要大量的标注数据。
- 卷积神经网络(CNN)和(循环神经网络)RNN 是当前最常见的两种神经网络。
- CNN 常用于图像处理,RNN 常用于语音识别和翻译。
- Xcode 的 Create ML 可以进行一些简单的模型训练工作。