

端午节期间,读完了《人工智能简史》。这是一本轻松的读物,书中并不涉及太多人工智能的专业知识,作者更多的是以一个轻松的心态来介绍人工智能的历史,以下是一些读书心得。
Ngram
Ngram 表示多个词合在一起的组合。谷歌提供了一个名为 Ngram 的工具,可以查询指定词在历史上出现的频率,其地址是:https://books.google.com/ngrams。在书中,作者通过比较「United States are」和「United States is」在历史上出现的 频率,看出美国人是何时开始认同美国作为一个统一的国家的。这可以看出大数据即使在历史学科,也能提供非常有力的证据。
有意思的是,Ngram 的用处远远不止于此。例如,我们可以用 Ngram 来做语法纠错,比如你发现历史上「as soon as possible」出现的次数非常高的时候,你就可以让机器把这个理解成一个高频搭配,当某个人把「soon」拼写成「soom」的时候,你就可以基于上下文来帮他做拼写的纠正。
你看,基于大数据的统计非常简单,又非常有效。有些时候,他有效得让人感觉到吃惊,甚至在基于大数据的统计分析来看,任何人类的经验都可能是狭隘或者有害的。比如在书中就提到,机器翻译领域,很多专家都认为语言学知识对翻译没什么用处,有些时候还会起反作用。比如 IBM TJ Wason 研究中心的机器翻译小组成员贾里尼克(Frederick Jelinek)以及谷歌翻译团队的欧赫(Franz Josef Och)就都表达过上述观点。
在学术上,语法派和统计派一直相互争论。不过我现在认为统计派越来越占上风了,特别是统计派将大数据的处理方式改成深度学习之后。Google 和 Facebook 分别使用 RNN 和 CNN 两种神经网络来训练,最终在机器翻译领域取得突破性进展。
那么问题来了,这么翻译出来的东西,机器真的能够理解吗?也许翻译本身根本就不是理解问题,翻译本身并不需要理解,翻译只是翻译,只是数据问题,而不是语义问题。
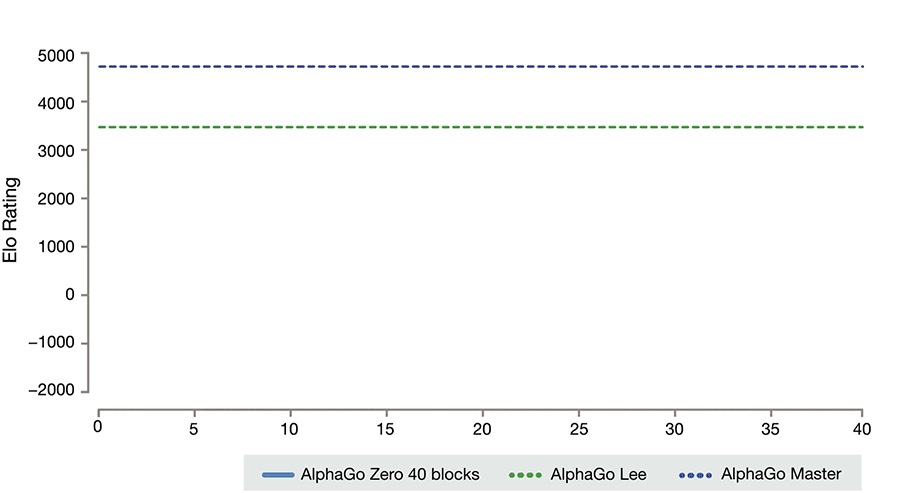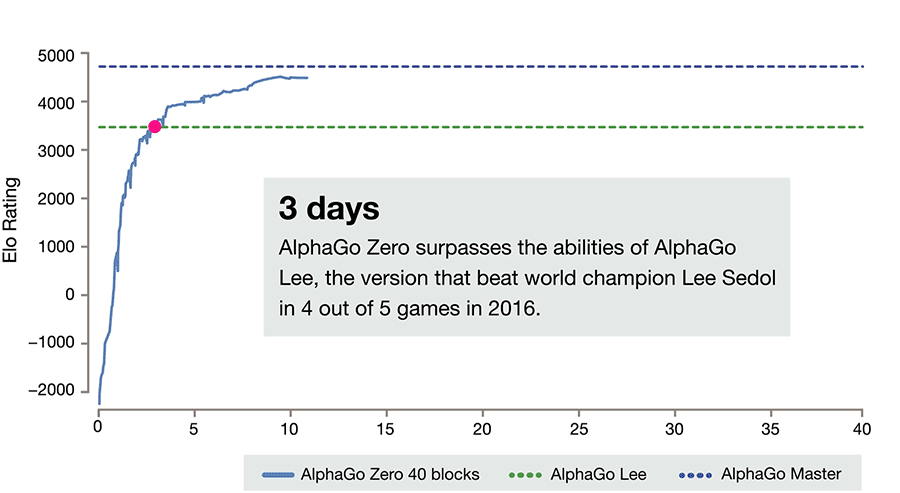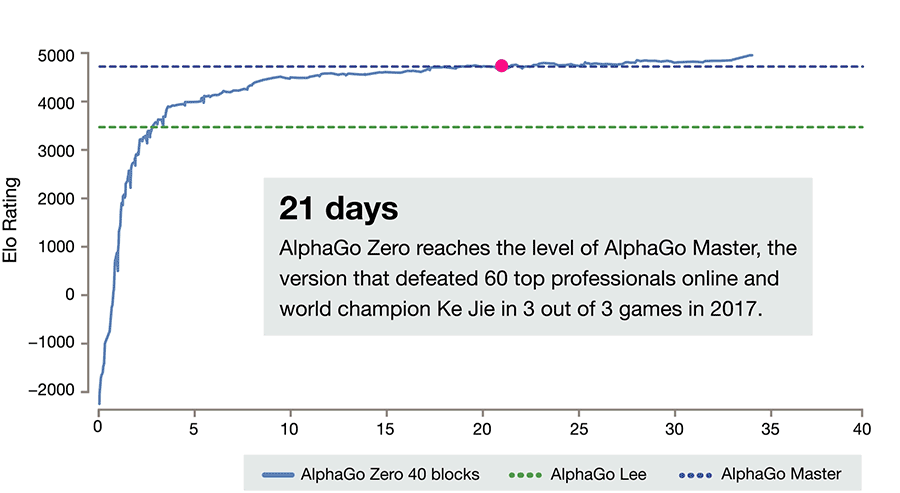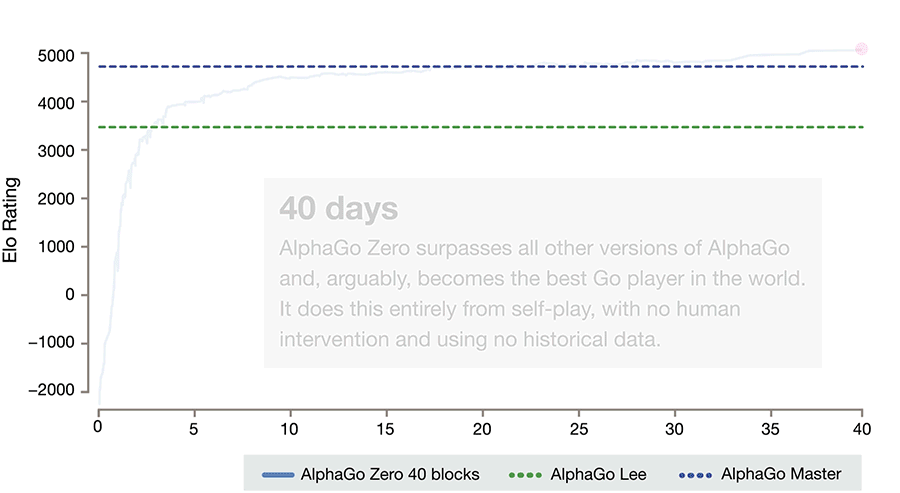
除了在翻译领域,人类发现自己的经验没什么用,在围棋领域也是同样。AlphaGo Zero 仅仅过 40 天的自我学习,就超过了那些学习了大量人类棋手的前辈:AlphaGo Lee 和 AlphaGo Master 。这除了说明机器自我对弈的强化学习(Reinforcement Learning)的效果超强之外,也同时宣告人类的经验在有时候真的是负担。
知识图谱和机器阅读
维基百科搭建了一个给全人类的免费知识库,但是,机器却不能轻易读懂这些内容。为了让机器更加容易处理各类信息,Google 在 2012 年发起了知识图谱(Knowledge Graph)的 项目。
Google 并不是从零开始这个项目,它其实在 2010 年收购了一家名为 Metaweb 的公司,而这家公司运营着一个拥有 4000 万代表知识实体的数据库:Freebase。Freebase 的数据是结构化的,这样机器可以很方便地对知识进行再处理。相对应的,维基百科在 2016 年的文章数仅为 1000 万篇。
2016 年 Google 停止对 Freebase 更新,并把所有数据捐给 Wikidata,Wikidata 是维基百科的母公司。除了 Wikidata 外,还有几个开源的知识图谱,如 DBpedia, Yago, SUMO 等。
当知识图谱足够大的时候,它的回答能力会大的惊人。2011 年 IBM 的沃森 (Watson) 在美国电视智力竞赛节目《危险边缘》(Jeopardy!)中击败人类选手,获得百万美元大奖,就是利用了包括 WordNet,DBpedia 和 Yago 等各种知识图谱。
除了将数据更加结构化外,研究人员也在不停地改进机器阅读自然文章的能力。相比于将原有的知识结构化,直接让机器读懂人类语言的文章虽然挑战更大,但是收益也是非常明显的。
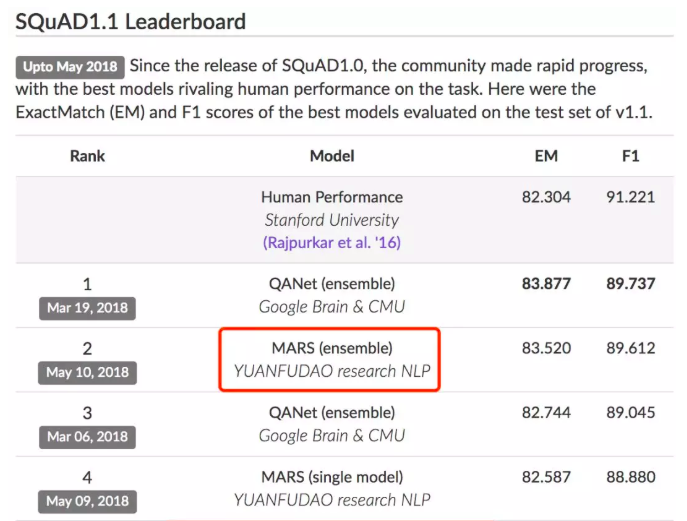
对于这点,全世界的 AI 公司都在努力,包括我们公司。吹牛逼时间到了:我们猿辅导公司最近就因此出现在互联网女皇的报告中,因为我们在斯坦福的问答评测 SQuAD1.1 中排名第三(其实现在已经第二了)。量子位的 一篇文章 深度介绍斯坦福的这个评测集。
未来
在我们公司参加的另一个机器阅读理解评测集 MSMARCO 中,我们有幸拿到了第一,并且超过了人类的基准水平。基准水平可以理解为人类的平均水平。这让我再一次作为人类产生了危机感。
或许有一天,人工智能不光在围棋,象棋,驾驶这些有限场景下代替人,还能比人类更加理解文字,更快吸收知识,最终全面超越人类。
在《未来简史》中,作者把这个潜在新物种叫做神人(Homo Deus),新物种在我们这个时代是否会出现,让我们拭目以待。