

最近收到图灵编辑刘美英老师赠送的《图解 DeepSeek 技术》,全书只有不到 100 页,而且配套了大量插画,让原本让人生畏的大语言模型底层技术,变得不那么难懂。
本书非常适合对于大语言模型零基础的读者,作为入门书籍。以下是我的一些笔记。
缩放定律(Scaling law)
深度学习的底层原理其实缺乏科学论证,最终只能用“涌现”这种现象来描述我们观察到的实验结果。这个实验结果就是:当我们提高模型规模的时候,模型的表现也会越来越好。
于是,我们通过三个要素来提升模型的规模,分别是:参数量、数据量和计算量(如下图)
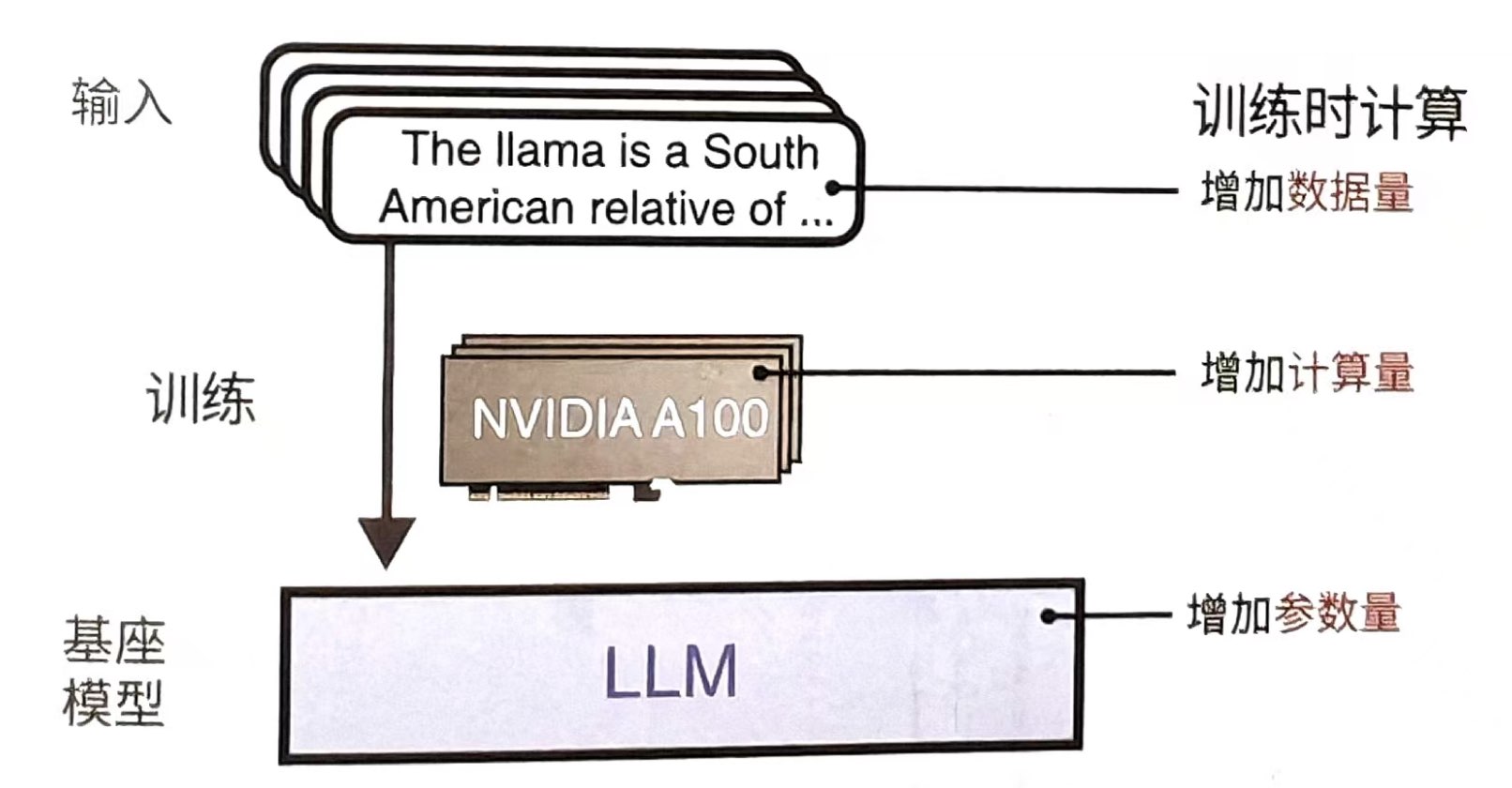
我对“涌现”的理解:这个世界上很多事情都是从量变到质变,大模型“涌现”出来的智能,再一次体现了这种自然界常见的现象。比如:
- 水在温度上升的时候,形态一直是液态,直到上升了 100 度,就开始沸腾,转化为气态。
- 股市,前期积累的泡沫越来越大,最后泡沫破灭的时候,就会一下子跌特别多。
我对缩放定律的理解:缩放定律在自然界中也非常常见,很多变化不是线性的,而是幂律(power law)的。比如:
- 财富的集中度。在美国前 10% 的人持有超过 90% 的财富。
- 公司的营收排名。排名每上升一名,营收可能是下一名的 2 倍。
- 明星或达人的收入。关注度每上升一位,收入可能翻翻。
- 28 原理。决定一件事情的最主要的 20% 因素,占据了 80% 的权重。
深度思考
缩放定律把大家的精力都集中在堆参数量和堆算力上,但是研究人员发现,如果让模型在输出答案的过程中进行“长思考”,答案会变得显著得好。于是,除了在训练阶段发力外,我们通过让模型在生成答案时消耗更多资源,来提升答案的质量。这就是现在变得普遍的“深度思考”模式(如下图)。

在我的理解下,深度思考模式类似于《思考快与慢》一书中提到的人类的慢思考。人类大多数时候,是用直觉来决策的,因为这样效率最高,而且直觉通常来源于大量的经验(预训练),通常情况下是对的。但是,对于一些重大的决策,人类就会启动慢思考(深度思考),会花大量的时间和精力来论证自己的想法是否正确,以保证重大决策的质量。
蒸馏(Distill)
DeepSeek-R1 是一个拥有 6710 亿个参数的庞大模型,这使得部署和使用它都需要强大的硬件支持。但是 DeepSeek 创新性的开创了将自己的推理能力蒸馏到别的小模型(比如 Qwen-32B)上的方法。
具体来说,研究团队用 DeepSeek 当老师模型,让 Qwen 当学生模型。当两个模型接收到相同的提示词后,均需要输出一个词元概率分布。在训练过程中,学生模型需要紧密跟随老师模型的分布特征(如下图)。
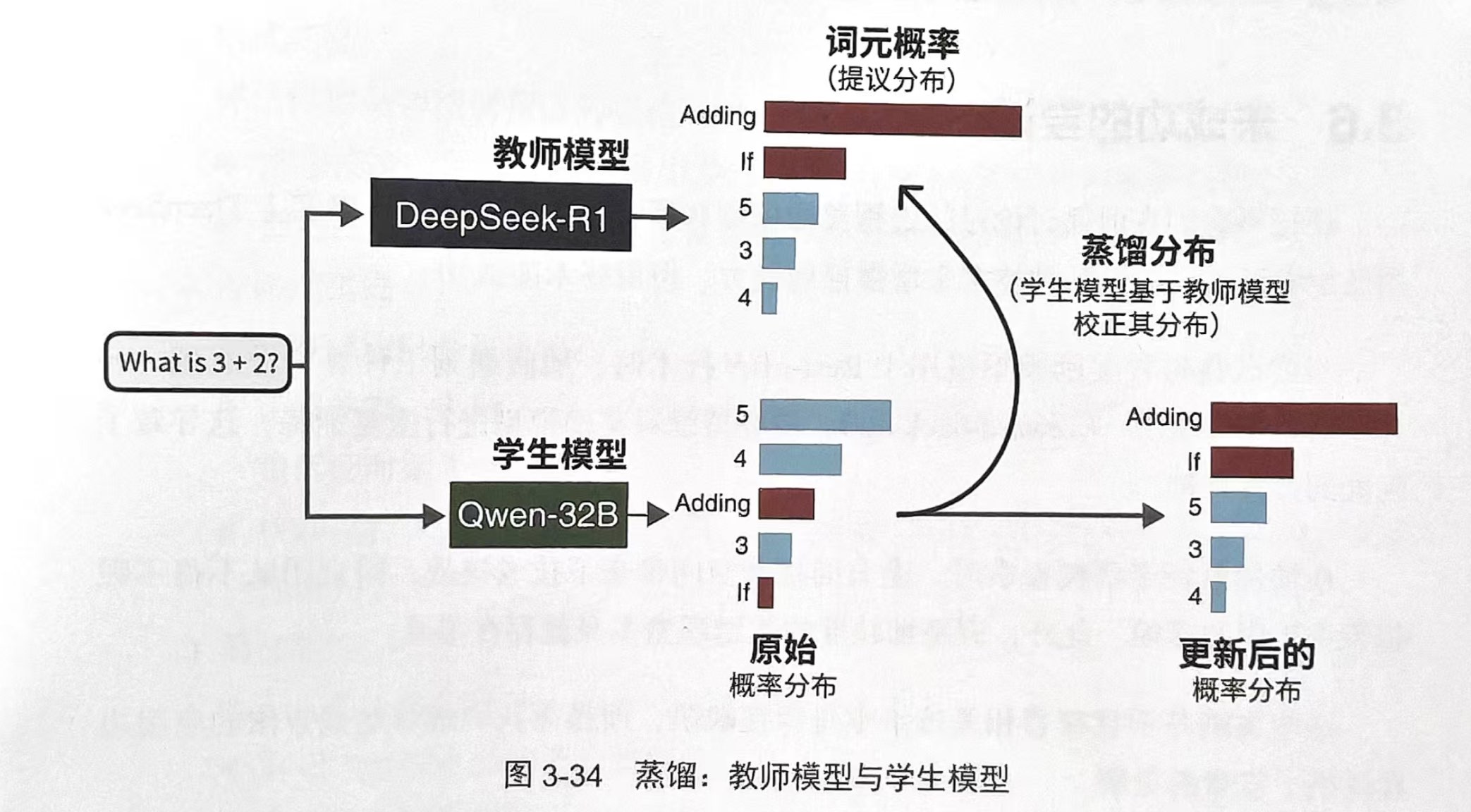
以上过程在 80 万个样本的训练下,这些小模型学会了 DeepSeek 的思维方式,与蒸馏前相比,能力有大幅的提升。
在我的理解下,这也非常类似人类的“师徒学习模式”。我在计算机行业,我们行业的毕业生刚进企业的时候,都会有一个导师(mentor)进行一对一指导。最终帮助我们这些职场小白快速融入行业,写出高质量的代码。
以上。